Live · in production · case-study system
Frank.ink — an agent you can hand a task to.
A stateful agentic AI companion. You give it a brief in plain language; it runs in the background — across mail, browser, files, your own machines via a private tunnel — and comes back with the work done, not a transcript of how it would do it.
Frank.ink is a multi-tenant agentic AI platform. Each user runs their own isolated master Frank, which can spawn purpose-built specialist Franks for individual projects — long-running tasks that need their own memory, tool access, and execution scope.
Unlike a chat product, Frank is built around persistence. A specialist Frank keeps state between sessions: relationship graph, voice drift, pacts with the user, project memory, ongoing TODOs. You can close the tab. It keeps working.
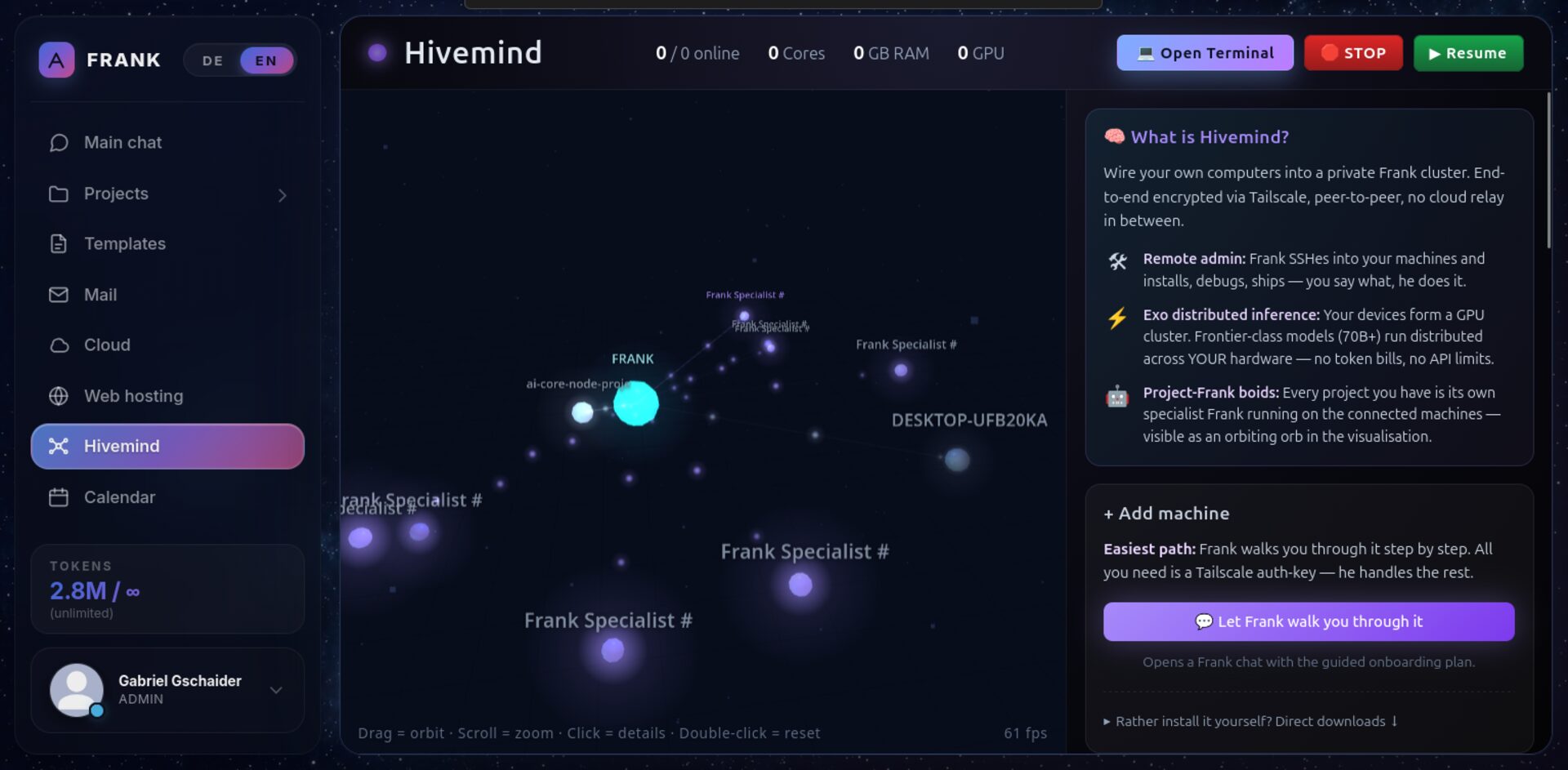
The platform runs on a single small VPS, augmented by user-provided hardware (laptops, desktops, servers) joined into a private Tailscale tunnel. That distributed layer is called Hivemind — every connected machine becomes accessible to the user's own Franks for SSH-grade administration and computation, but never to anyone else's.
Master chat
A single conversation that orchestrates everything — projects, mail, files, system tasks.
Project Franks
Specialist agents per project, with isolated state, tools, and long-running heartbeats.
Mail · Cloud · Calendar
Read-and-act-on-behalf via IMAP/SMTP, R2 object storage, and CalDAV. Never deletes, never mass-sends without sign-off.
Web hosting
Each user gets a slug — name.frank.ink — and can have Frank build them a site live, deployed behind a wildcard cert.
Hivemind
Connect your own machines via Tailscale. Frank SSHs in, installs, debugs, ships — under your audit log.
Marketplace + Browser
Structured searches across Amazon + eBay with real listings, plus a sandboxed Chromium for arbitrary web tasks.
Identity Forge
Each project Frank builds its own relationship graph with the user — pacts honored or broken, voice drift, mood.
Terminal
Browser-resident shell sandboxed per chat with bwrap + gVisor — full root within its own filesystem, invisible to peers.
When the user pastes a screenshot or drag-drops an image, Frank routes it through a four-stage CPU-only vision pipeline. No GPU is involved. The stages, in order:
Stage 1
OCR
PaddleOCR · text layer
Stage 2
Object det.
YOLOv8n · INT8 · 80 COCO classes
Stage 3
Open-vocab
CLIP-B/32 · INT8 · ~280 phrases
Stage 4
Embed
DINOv2 · scene similarity
Stage 5
Narrative
VLM-style 2–5 sentence describe
A smart router decides which stages to run. A pure UI screenshot short-circuits the semantic models — OCR + a glance at the layout is enough. A photo with possible people, objects, or scenes runs the full pipeline. The final stage writes a natural-language summary ("a robot head sliced open in profile, copper filament behind the eye…") — what Frank then reasons about.
p50 latency: ~900 ms on 1 vCPU. Concept recall: 95% on a 6-image internal benchmark. The whole pipeline costs roughly the same as one extra LLM round-trip — and the user's screenshot never leaves the institute's VPS.
Voice in Frank is push-to-talk by default, two stages each direction:
Stage 1
Mic
WebRTC capture · 16 kHz
Stage 2
STT
faster-whisper · small · INT8
Stage 3
LLM turn
Frank's normal text path
Stage 4
TTS
Piper · per-user voice profile
Stage 5
Stream
WS frames · sub-200ms first byte
STT runs locally on the VPS — recordings are not sent to a third party. TTS uses Piper voices selected per user; the voice drift system slowly shifts pace and intonation toward the user's own speech patterns over time (the same drift mechanism that shapes Frank's text voice). End-to-end latency on a short user message is roughly 1.2–1.8 seconds.
§5 · The footprint
One small VPS. Four vCPU. Eight GB. No GPUs in the loop.
Frank's production deployment runs on a single Hetzner-class VPS augmented by user-provided Hivemind machines. Inference is rented from external token providers; everything else — orchestration, state, presence, vision, audio, sandboxes — runs on the box itself.
4 vCPU
Compute budget
8 GB
RAM ceiling at peak
0 GPU
Inference rented, not run locally
900 ms
p50 vision pipeline · 1 vCPU
95%
Concept-recall · internal 6-image bench
93%
Prompt-cache hit-rate · chitchat path
~$0.06
Cost per 20-turn chitchat session
5 sub
Subsystems ablated · case-study
Numbers are operational, not benchmark-curated. Vision and audio latencies measured on the production VPS under typical load; cost figures from real provider billing dashboards after the cache double-count bug was patched (May 12, 2026).
The institute's working paper used this exact system as its case study — five subsystems ablated, one at a time.
Read the paper→