Live · in Produktion · Fallstudien-System
Frank.ink — ein Agent, dem du eine Aufgabe übergeben kannst.
Eine zustandsbehaftete agentische KI-Begleitung. Du gibst ihm einen Auftrag in normaler Sprache; er läuft im Hintergrund — über Mail, Browser, Dateien, deine eigenen Maschinen via privatem Tunnel — und kommt mit erledigter Arbeit zurück, nicht mit einem Protokoll, wie er es tun würde.
Frank.ink ist eine multi-mandantenfähige agentische KI-Plattform. Jeder Nutzer betreibt seinen eigenen isolierten Master-Frank, der gezielt entwickelte Spezialisten-Franks für einzelne Projekte hervorbringen kann — langlaufende Aufgaben, die eigenen Speicher, Werkzeugzugriff und Ausführungs-Scope benötigen.
Anders als ein Chat-Produkt ist Frank um Persistenz herum gebaut. Ein Spezialisten-Frank behält Zustand über Sitzungen hinweg: Beziehungs-Graph, Stimm-Drift, Pakte mit dem Nutzer, Projekt-Erinnerung, laufende TODOs. Du kannst den Tab schließen. Er arbeitet weiter.
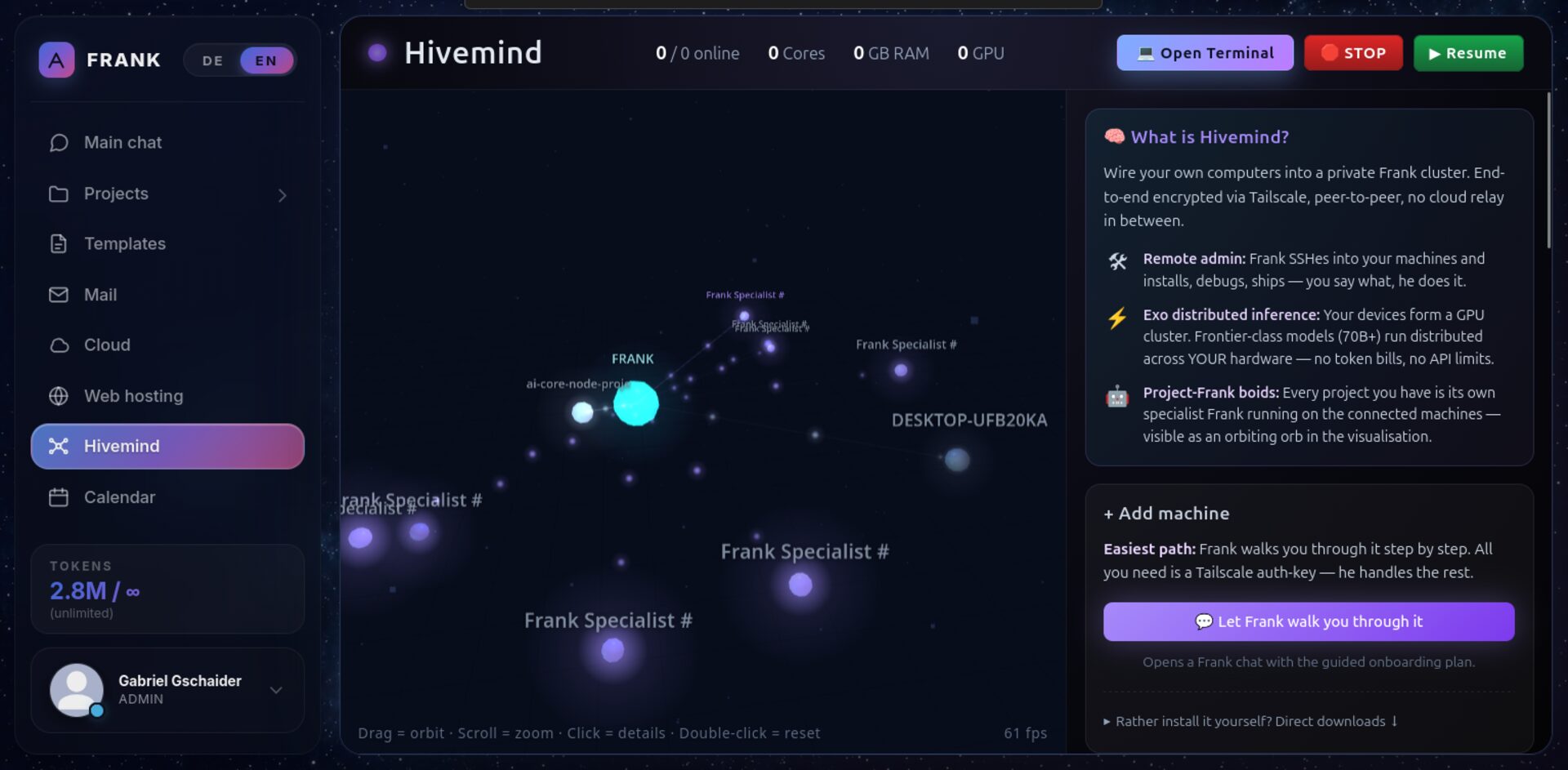
Die Plattform läuft auf einem einzelnen kleinen VPS, erweitert um nutzereigene Hardware (Laptops, Desktops, Server), die in einen privaten Tailscale-Tunnel eingegliedert ist. Diese verteilte Schicht heißt Hivemind — jede verbundene Maschine wird für die eigenen Franks des Nutzers als SSH-Administration und Rechenressource zugänglich, niemals aber für die eines anderen.
Master-Chat
Ein einziger Gesprächsfaden, der alles orchestriert — Projekte, Mail, Dateien, System-Aufgaben.
Projekt-Franks
Spezialisten-Agenten pro Projekt, mit isoliertem Zustand, Werkzeugen und langlaufenden Heartbeats.
Mail · Cloud · Kalender
Lesen und Handeln im Auftrag via IMAP/SMTP, R2-Objektspeicher und CalDAV. Löscht nie, versendet nie massenhaft ohne Freigabe.
Web-Hosting
Jeder Nutzer bekommt einen Slug — name.frank.ink — und kann sich von Frank live eine Seite bauen lassen, deployed hinter einem Wildcard-Zertifikat.
Hivemind
Verbinde deine eigenen Maschinen via Tailscale. Frank loggt sich per SSH ein, installiert, debuggt, deployed — unter deinem Audit-Log.
Marktplatz + Browser
Strukturierte Suche über Amazon und eBay mit echten Einträgen, plus ein sandboxed Chromium für beliebige Web-Aufgaben.
Identity Forge
Jeder Projekt-Frank baut seinen eigenen Beziehungs-Graphen zum Nutzer auf — eingehaltene oder gebrochene Pakte, Stimm-Drift, Stimmung.
Terminal
Browser-Shell, pro Chat mit bwrap + gVisor sandboxed — voller Root im eigenen Dateisystem, unsichtbar für andere.
Wenn ein Nutzer einen Screenshot einfügt oder ein Bild per Drag-and-Drop ablegt, leitet Frank es durch eine vierstufige rein CPU-basierte Vision-Pipeline. Keine GPU im Einsatz. Die Stufen der Reihe nach:
Stufe 1
OCR
PaddleOCR · text layer
Stufe 2
Object det.
YOLOv8n · INT8 · 80 COCO classes
Stufe 3
Open-vocab
CLIP-B/32 · INT8 · ~280 phrases
Stufe 4
Embed
DINOv2 · scene similarity
Stufe 5
Narrative
VLM-style 2–5 sentence describe
Ein intelligenter Router entscheidet, welche Stufen laufen. Ein reiner UI-Screenshot schaltet die semantischen Modelle aus dem Pfad — OCR + ein Blick auf das Layout reichen. Ein Foto mit möglichen Menschen, Objekten oder Szenen durchläuft die volle Pipeline. Die letzte Stufe schreibt eine natürlichsprachliche Zusammenfassung ("ein Roboterkopf im Profil aufgeschnitten, Kupferdraht hinter dem Auge…") — worüber Frank dann nachdenkt.
p50-Latenz: ~900 ms auf 1 vCPU. Concept-Recall: 95 % auf einem internen 6-Bild-Benchmark. Die ganze Pipeline kostet ungefähr so viel wie ein zusätzlicher LLM-Round-trip — und der Screenshot des Nutzers verlässt nie den VPS des Instituts.
Sprache in Frank ist standardmäßig Push-to-Talk, zwei Stufen pro Richtung:
Stufe 1
Mic
WebRTC capture · 16 kHz
Stufe 2
STT
faster-whisper · small · INT8
Stufe 3
LLM turn
Frank's normal text path
Stufe 4
TTS
Piper · per-user voice profile
Stufe 5
Stream
WS frames · sub-200ms first byte
STT läuft lokal auf dem VPS — Aufnahmen werden nicht an Dritte gesendet. TTS verwendet Piper-Stimmen, pro Nutzer ausgewählt; das Voice-Drift-System verschiebt Tempo und Intonation über die Zeit langsam in Richtung des Sprechmusters des Nutzers (derselbe Drift-Mechanismus, der Franks Text-Stimme prägt). Ende-zu-Ende-Latenz bei einer kurzen Nutzer-Nachricht: etwa 1,2–1,8 Sekunden.
§5 · Der Fußabdruck
Ein kleiner VPS. Vier vCPU. Acht GB. Keine GPUs im Spiel.
Franks Produktions-Deployment läuft auf einem einzelnen VPS der Hetzner-Klasse, erweitert um nutzerbereitgestellte Hivemind-Maschinen. Inferenz wird von externen Token-Anbietern gemietet; alles andere — Orchestrierung, State, Präsenz, Vision, Audio, Sandboxes — läuft auf der Kiste selbst.
4 vCPU
Rechen-Budget
8 GB
RAM-Decke bei Spitze
0 GPU
Inferenz gemietet, nicht lokal
900 ms
p50 Vision-Pipeline · 1 vCPU
95%
Concept-Recall · interner 6-Bild-Benchmark
93%
Prompt-Cache-Trefferquote · Chitchat-Pfad
~$0.06
Kosten pro 20-Turn-Chitchat-Sitzung
5 sub
Subsysteme abladiert · Fallstudie
Die Zahlen sind operativ, nicht Benchmark-kuratiert. Vision- und Audio-Latenzen wurden auf dem Produktions-VPS unter typischer Last gemessen; Kostenangaben stammen aus echten Provider-Abrechnungs-Dashboards nach dem Patch des Cache-Doppelzähl-Bugs (12. Mai 2026).
Das Arbeitspapier des Instituts hat genau dieses System als Fallstudie verwendet — fünf Subsysteme einzeln abladiert.
Paper lesen→